Imagine you find a short movie script describing a scene between a person and their AI assistant. The script has what the person asks, but the AI's response has been torn off.

A script with the AI assistant's response torn off
Now imagine you have a machine that takes in text and predicts the next word. You could finish the script by feeding in what you have, grabbing the prediction, and repeating until the dialogue is complete.
The machine predicts the next word: "used"
Fed the growing text, the machine now predicts: "to"
When you interact with a chatbot, this is exactly what's happening.
What Is an LLM?
A large language model (LLM) is just a mathematical function that predicts the next word for any piece of text. Instead of committing to a single answer, it assigns a probability to every possible next word.
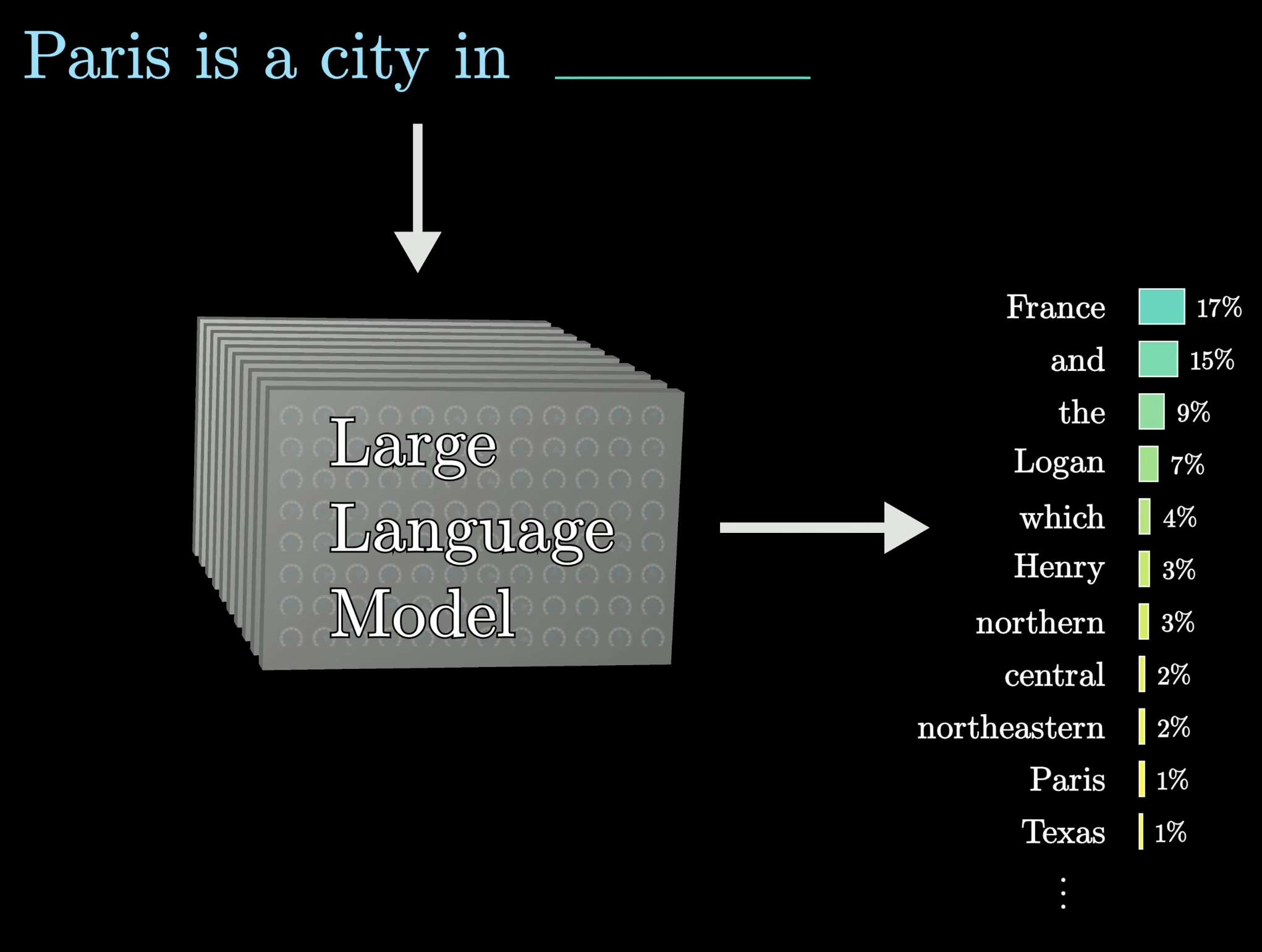
The model assigns probabilities to many possible next words
To build a chatbot, you start with some text describing an interaction between a user and a hypothetical AI assistant.

A description framing the interaction between user and AI assistant
Then you append whatever the user types.

The user's input is appended to the context
The model repeatedly predicts the next word this hypothetical assistant would say, and that's what gets shown to you. It doesn't always pick the most likely word as a bit of randomness makes the output sound more natural. That's why the same prompt can give you a different answer each time.

The model samples from its probability distribution to generate a response
How Does an LLM Predict the Next Word?
The model learns to make predictions by processing an enormous amount of text, most of it pulled from the internet.

LLMs are trained on enormous amounts of text from the internet
Think of training as tuning the dials on a really big machine. A language model's behavior is entirely determined by continuous values called parameters (or weights). Change the parameters, change the predictions.
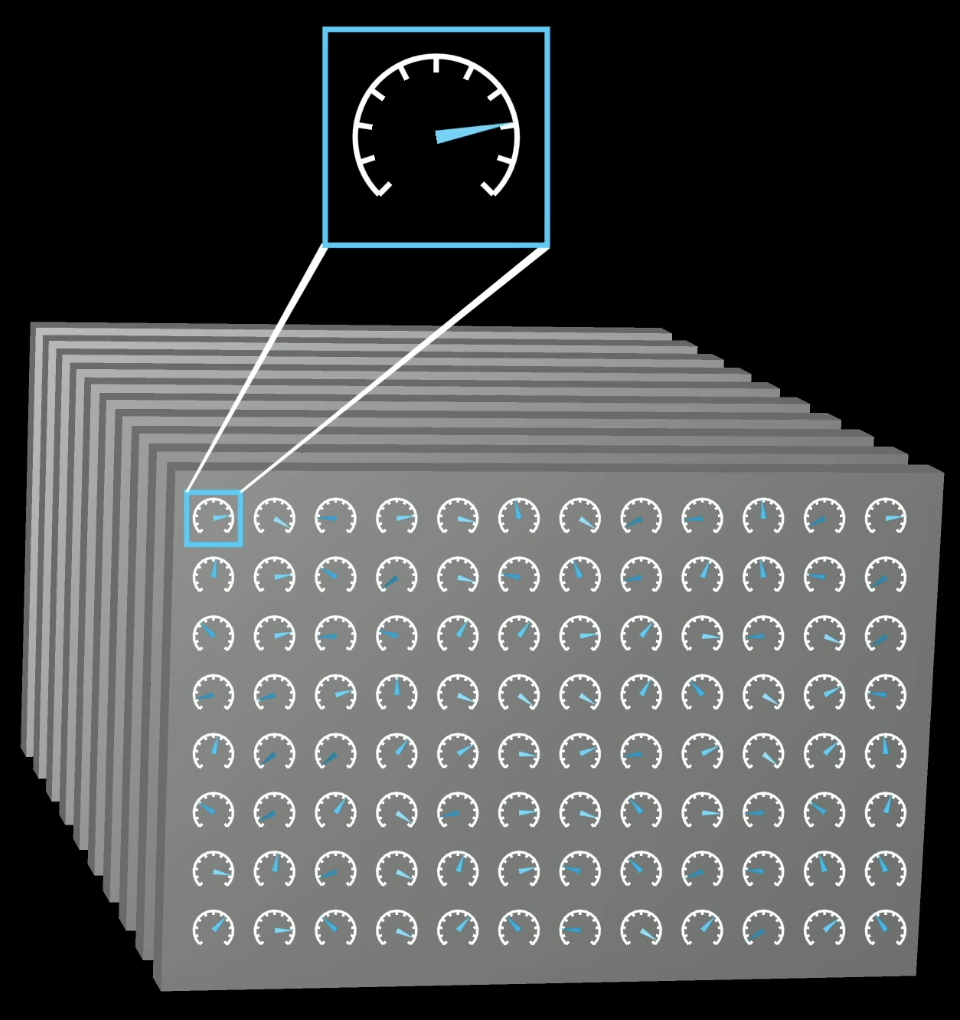
Model behavior is determined by tunable parameters (weights)
What puts the "large" in large language model? These things can have hundreds of billions of parameters.

Large language models can have hundreds of billions of parameters
Training: Predict the Last Word
No human sets these parameters by hand. The responses start out random (think word salad nonsense), but slowly refine their outputs through repeated exposure to text examples. You feed the model all but the last word of a text, then compare its prediction against the real answer.
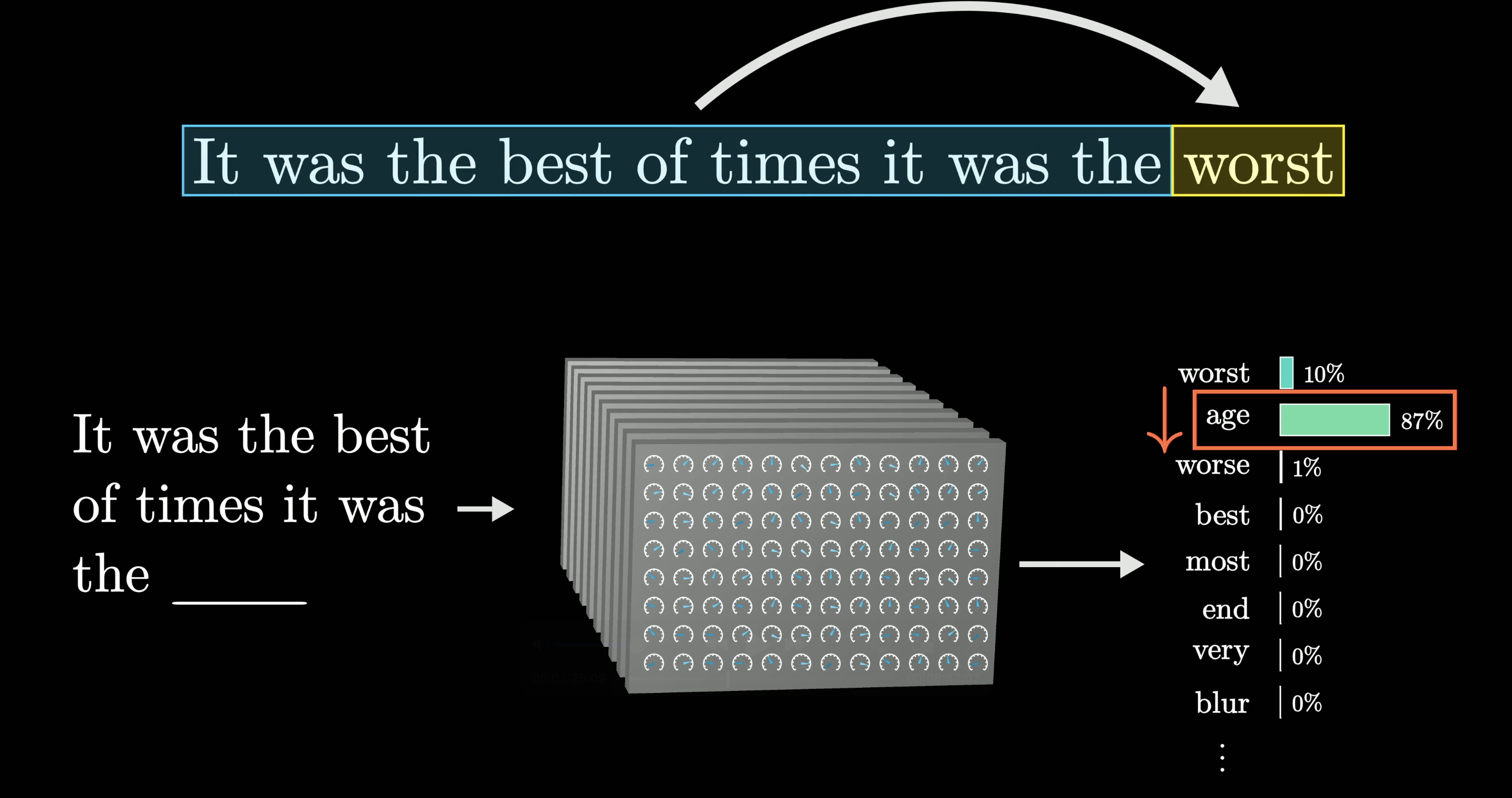
Training step: predict the next token, compare to the true last word
Backpropagation Updates the Weights
An algorithm called backpropagation then tweaks every parameter so the model becomes a little more likely to pick the right word and a little less likely to pick the wrong ones.

Backpropagation nudges weights to reduce prediction error
Repeat this for trillions of examples and the model can start making reasonable predictions on text it's never seen before. Given hundreds of billions of parameters and that much data, the computation involved is staggering.
Pretraining and RLHF
This process is called pre-training, and it's only part of the story. Auto-completing random internet text is a very different goal from being a helpful AI assistant.

Pre-training: learning next-word prediction from internet text
To bridge the gap, chatbots undergo reinforcement learning with human feedback (RLHF). Human workers flag unhelpful or problematic outputs, and their corrections further tune the model's parameters toward the kind of responses people actually want.

RLHF: human feedback steers the model toward preferred behavior
Why GPUs Matter
All that computation is only possible because of special chips designed to run many operations in parallel called GPUs.
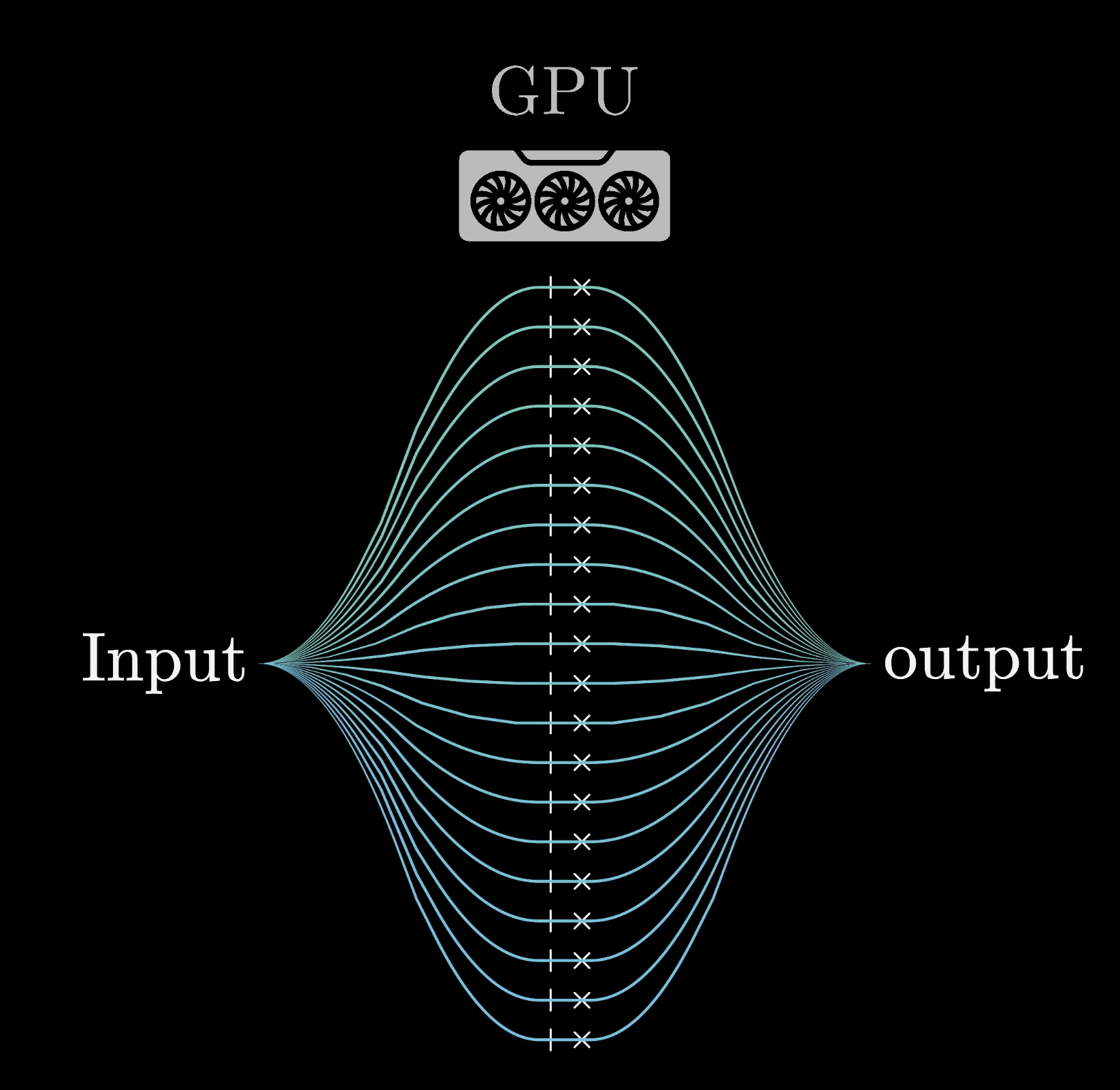
GPUs enable massive parallel computation
But not every model can take full advantage of them. Before 2017, most language models processed text one word at a time. Then a team at Google introduced a new architecture: the transformer.
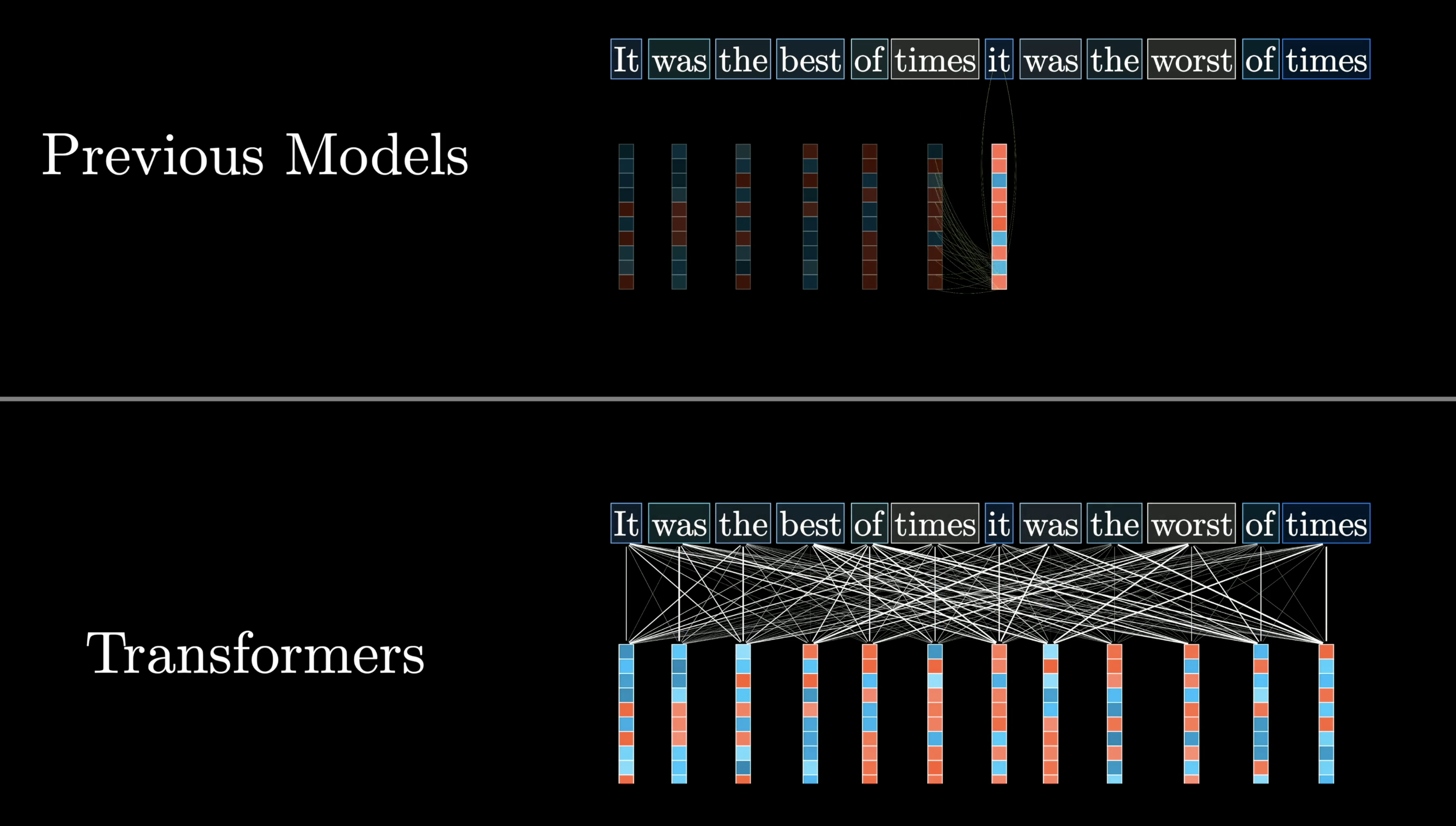
The transformer architecture was introduced by Google researchers in 2017
Instead of reading text from start to finish, transformers process it all at once in parallel.
Transformers
Step 1: Turn Words into Vectors
The first step inside a transformer is to associate each word with a long list of numbers called an embedding. Training only works with continuous values, so language has to be encoded numerically. Each embedding needs to capture the meaning of its word.
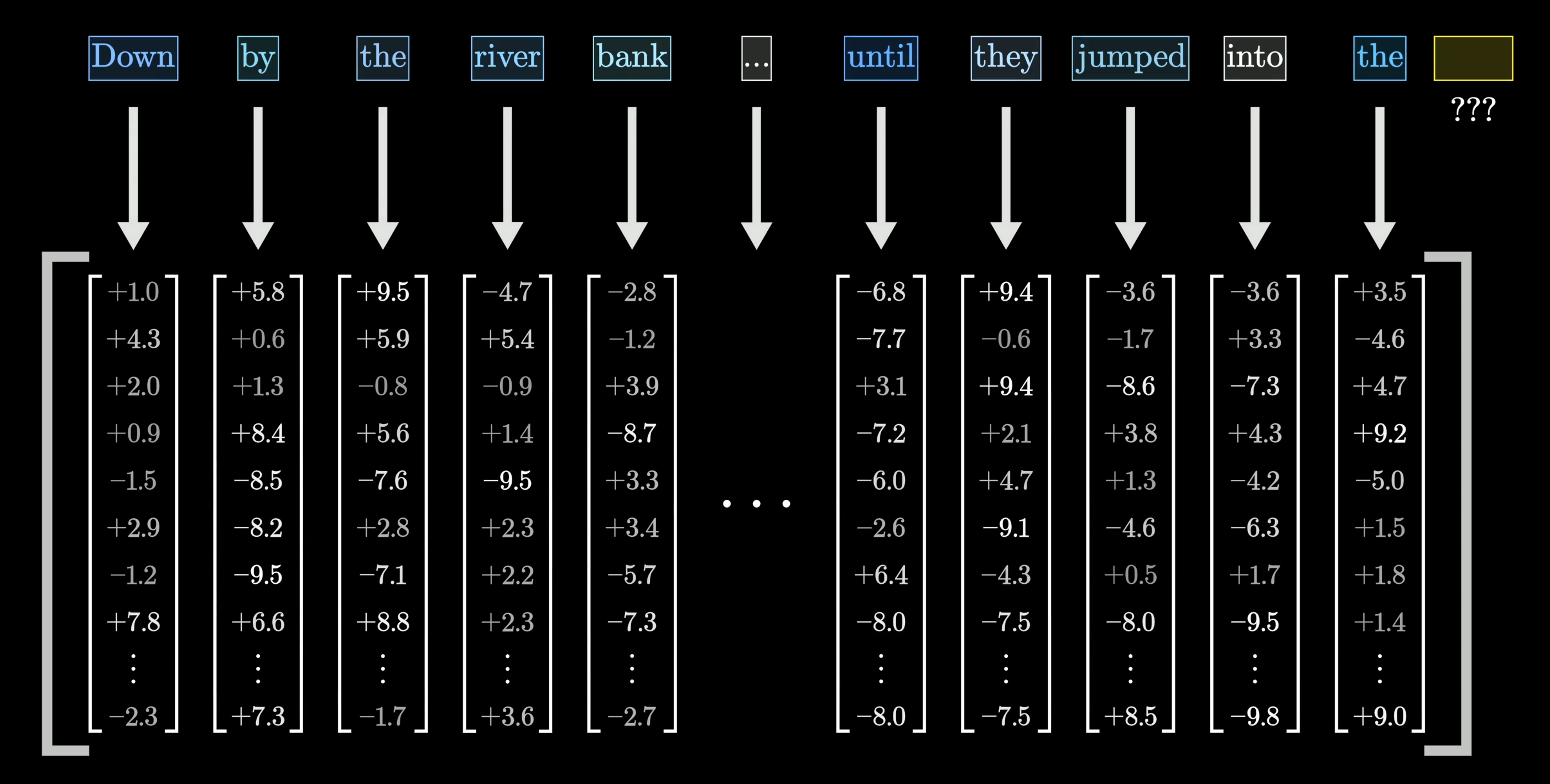
Token embeddings: words are mapped to lists of numbers (vectors)
Attention Refines Meaning Using Context
What makes transformers special is an operation called attention. It lets every embedding talk to every other embedding, refining their meanings based on context in parallel. For example, the numbers encoding "bank" get updated when the surrounding words are "river" and "jumped into," nudging the representation toward riverbank.
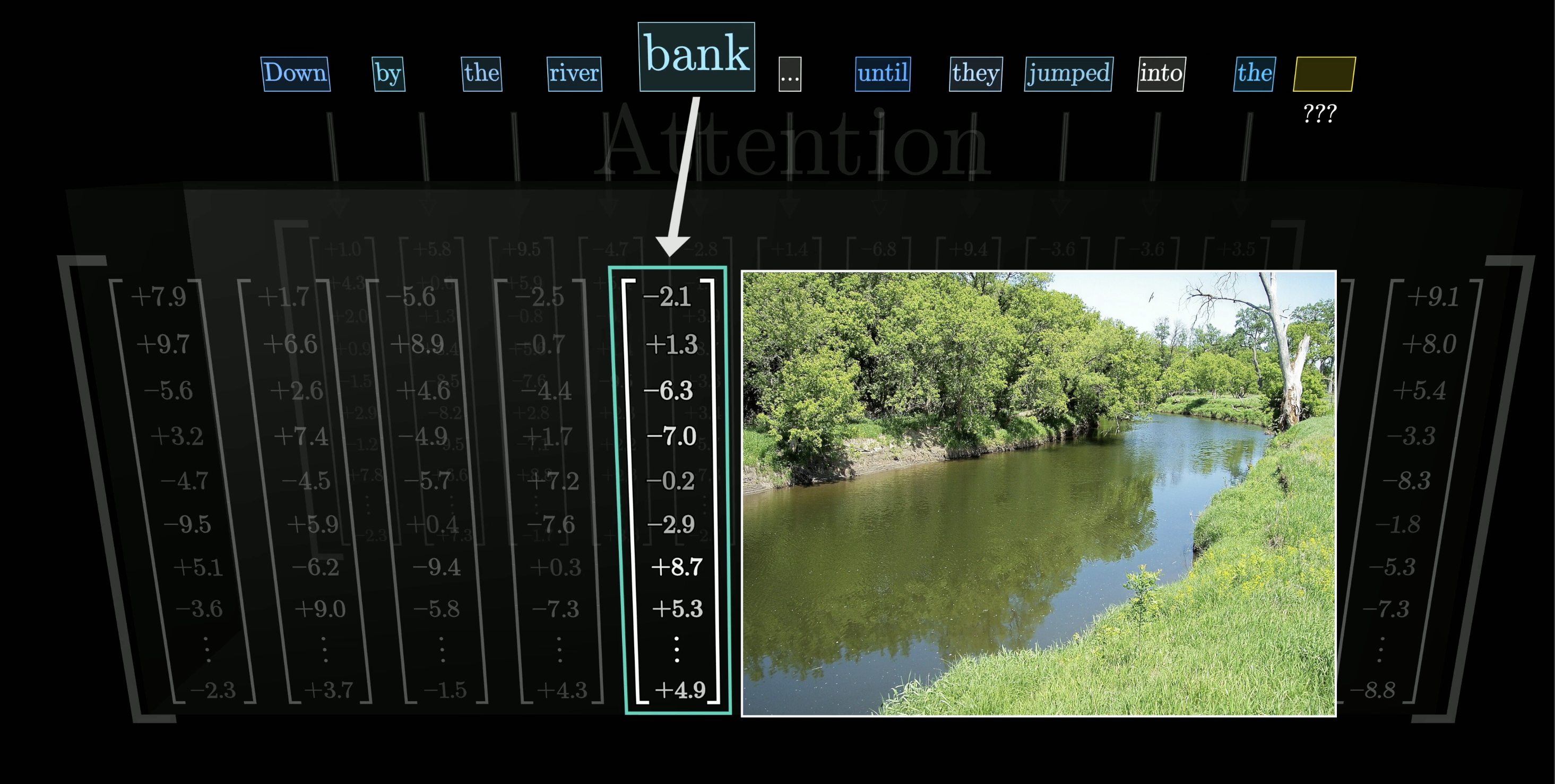
Attention contextualizes word meanings (e.g. "bank" near "river")
Feedforward Network and Repeated Layers
Transformers also include a feedforward neural network (MLP), which gives the model extra capacity to store patterns about language. Data flows through many alternating layers of attention and MLP blocks, and with each pass the embeddings get richer.
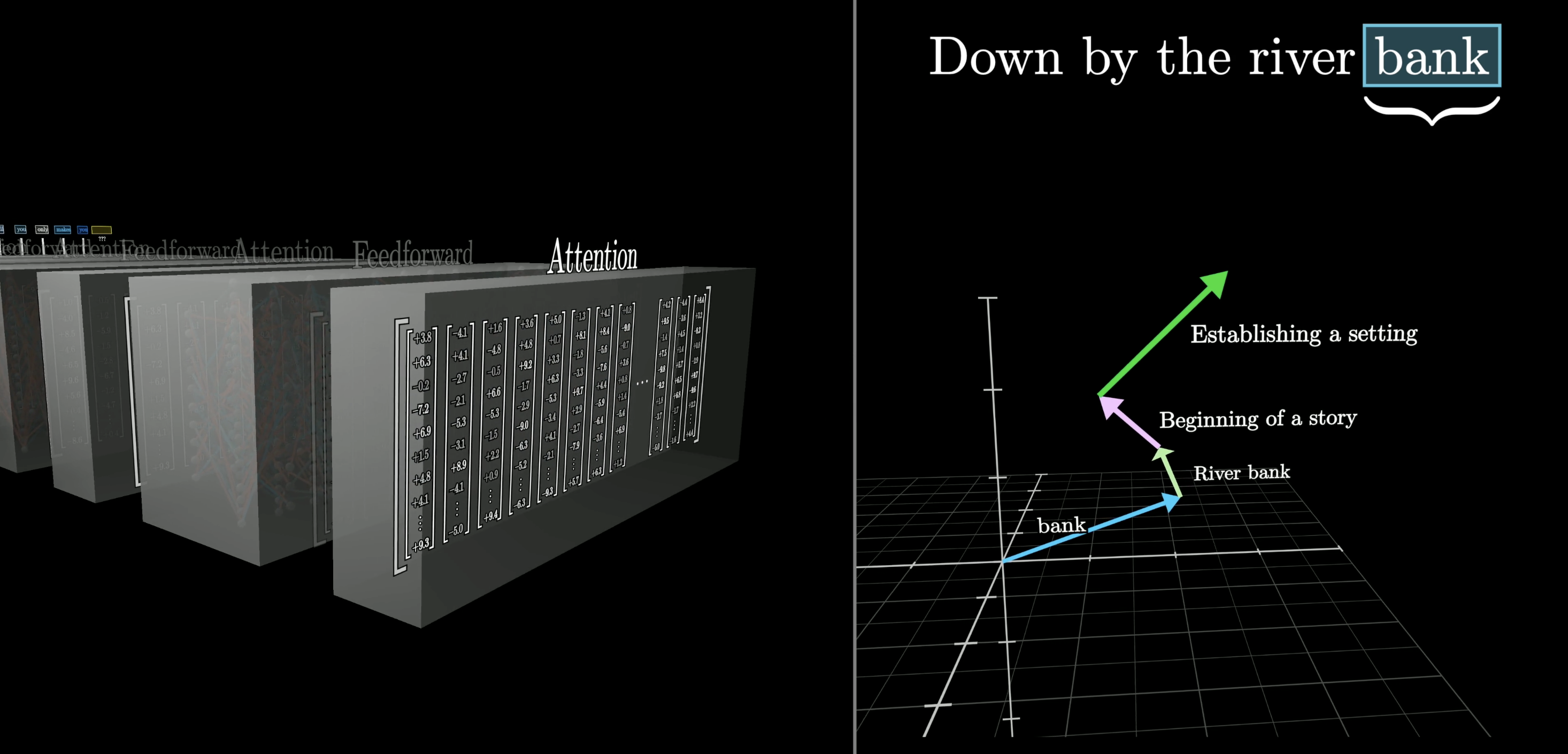
Data flows through many layers of attention + MLP blocks
Final Step: Predict the Next Token
At the end, one final function operates on the last vector in the sequence. By now it's been enriched by all the surrounding context and everything the model learned during training. The result is a probability for every possible next word.
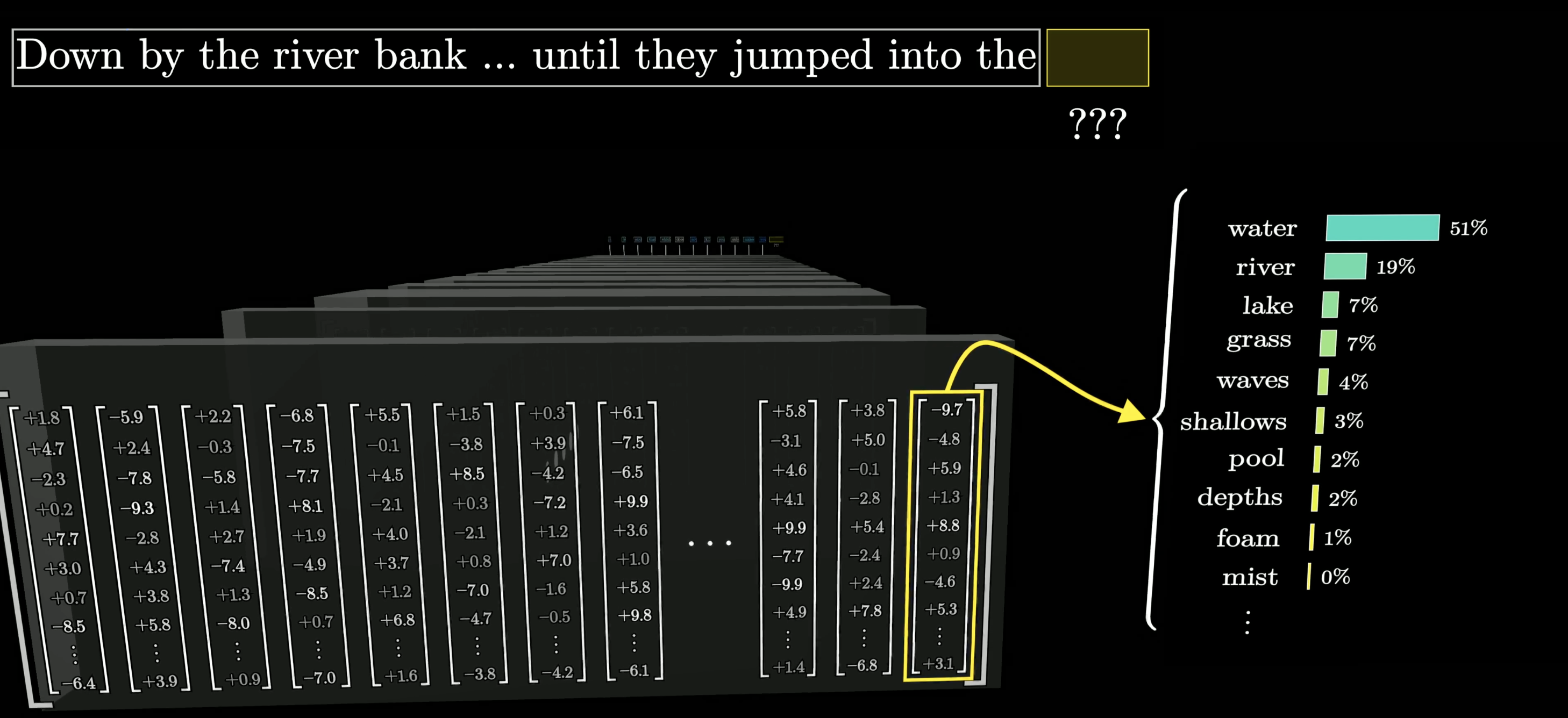
The final output: a probability for every possible next word
Researchers design the framework, but the specific behavior is emergent. It's a product of how those hundreds of billions of parameters shake out during training. That's what makes it so hard to understand why the model says what it says.
Conclusion
At the end of the day, an LLM is a predictive text engine. It's a massive mathematical function whose billions of parameters were tuned on internet-scale text, then refined with human feedback to be genuinely useful. Everything else (the chat interface, the seemingly intelligent responses) is just that prediction step on repeat.