What Is a GPT Model?
GPT stands for Generative Pre-Trained Transformer. Generative means it generates new text. Pre-trained means it was trained on large amounts of data before you ever touch it. The interesting part is the transformer, the architecture at the heart of the recent boom in AI.
What Exactly Is a Transformer?
A transformer is a type of neural network. Transformers power all sorts of models: voice-to-text, text-to-image, translation, you name it. The variant we care about (the one behind ChatGPT) takes in text and predicts what comes next as a probability distribution over all possible next chunks.
Once you have a model like this, generating longer text is simple: feed it some text, let it predict the next token, sample from the distribution, append the result, and repeat. That loop is what's happening when ChatGPT spits out words one at a time.
Tokens
The input text gets chopped into small chunks called tokens. These can be words, parts of words, or punctuation. Each token is then mapped to a vector (a list of numbers) called an embedding. The idea is that these vectors encode meaning: words with similar meanings end up close together in the embedding space.
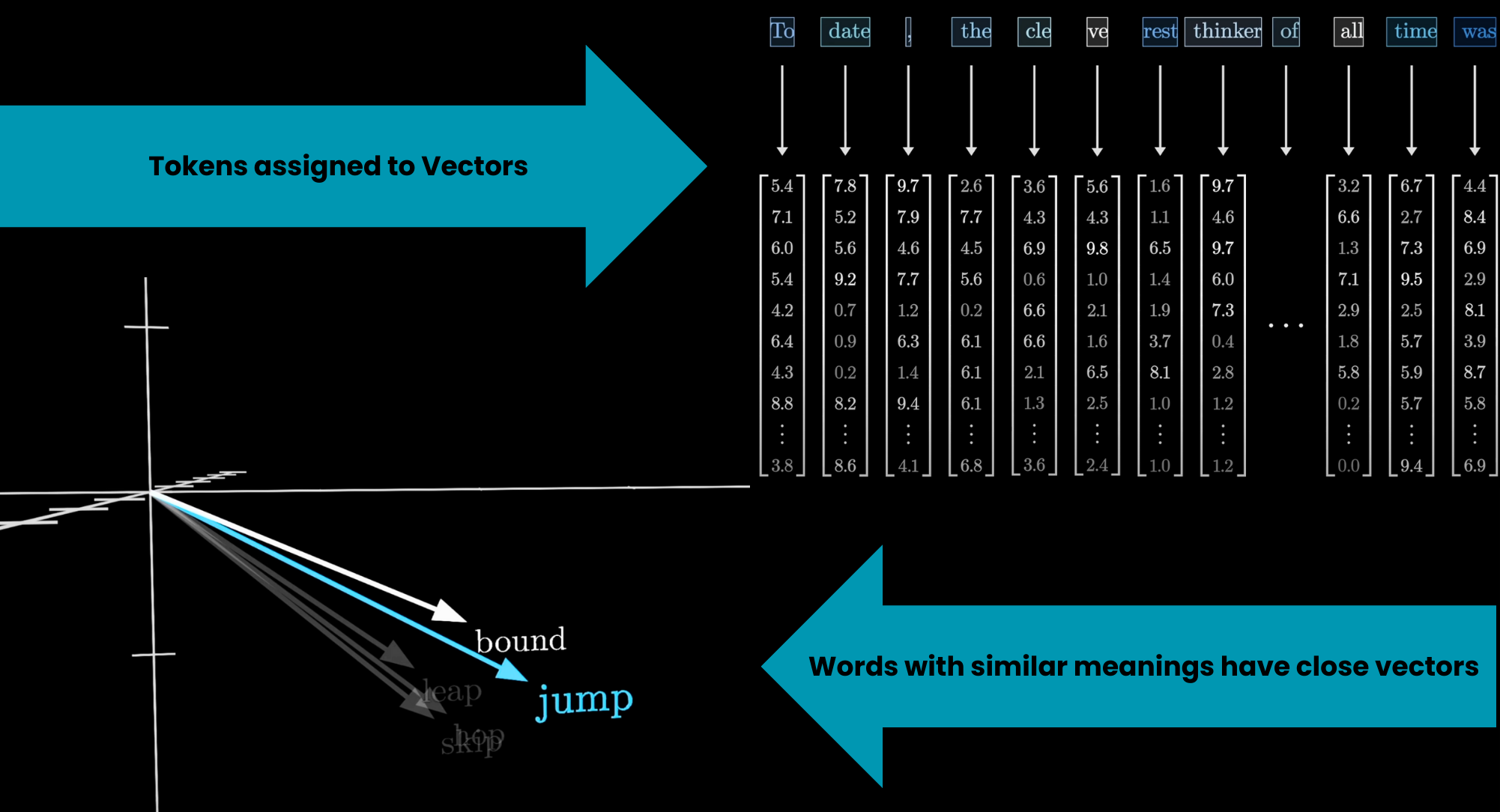
Tokenization breaks text into model-sized chunks
Attention Block
The vectors then pass through an attention block, where they talk to each other and update their values based on context. The word "model" means something different in "a machine learning model" than in "a fashion model." The attention block figures out which words in the context matter for updating the meaning of other words, and how to update them.
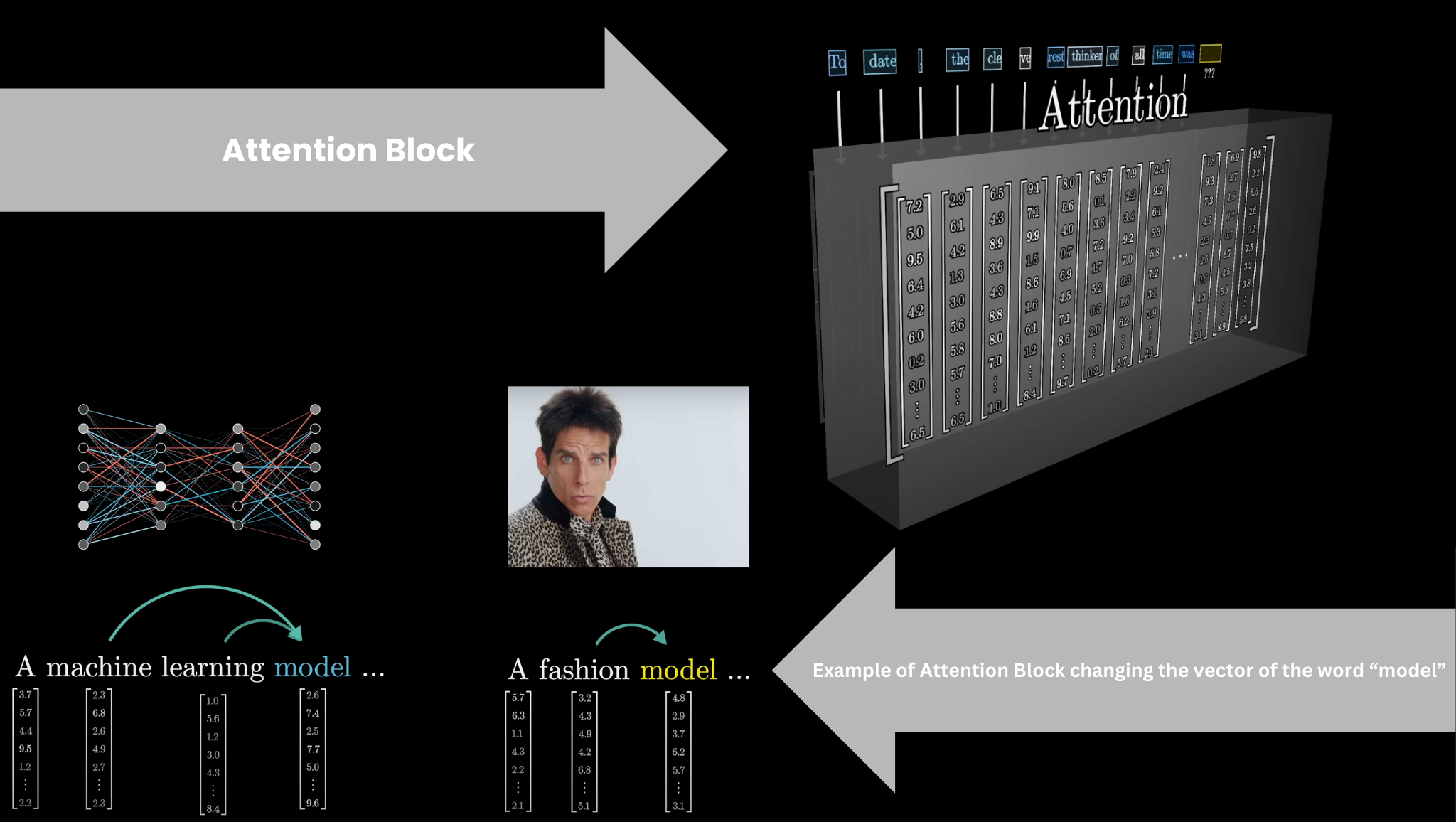
Attention: tokens influence each other based on relevance
Feed-Forward Layer (MLP)
After attention, the vectors pass through a multilayer perceptron (MLP), also called a feed-forward layer. Here, the vectors don't talk to each other. They all go through the same operation independently, in parallel.
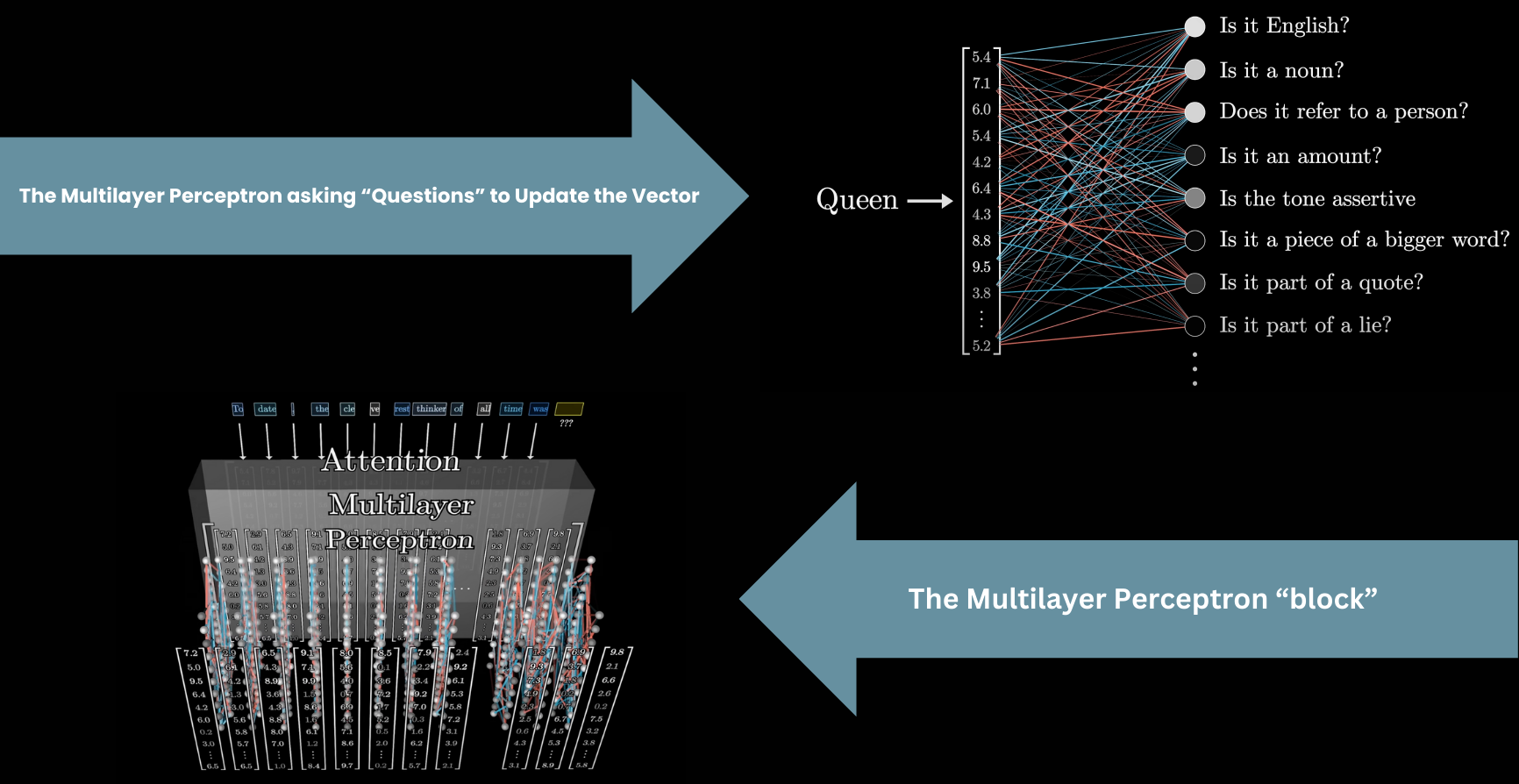
MLP: per-token transformation in parallel
Then it's another attention block, another MLP, and so on. Many alternating layers stacked deep (that's the "deep" in deep learning). After all those layers, the information needed to predict the next token gets packed into the last vector, which goes through one final step to produce a probability distribution over all possible next tokens.
Premise of Deep Learning
In machine learning, the data is what ultimately determines how a program behaves. Think of a model as a function with a bunch of adjustable knobs and dials. Your job as the engineer isn't to set those dials by hand, but to find a procedure that tunes them automatically from data.
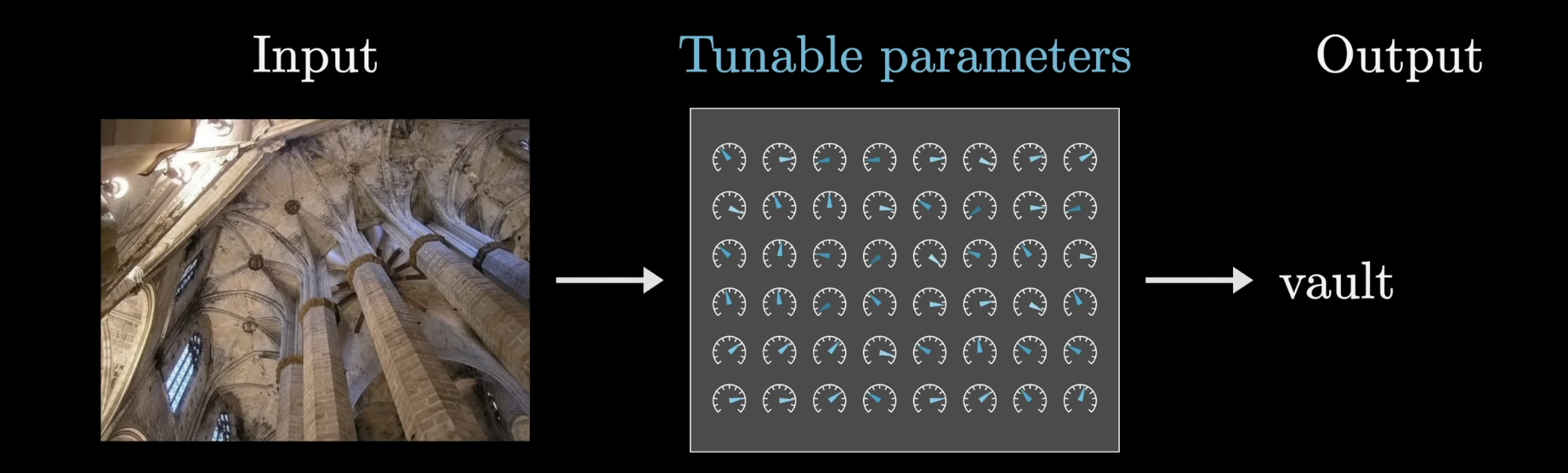
Training tunes parameters using data
The simplest form of machine learning is linear regression: fit a line (determined by slope and its y-intercept) to data points to predict future outputs from inputs.
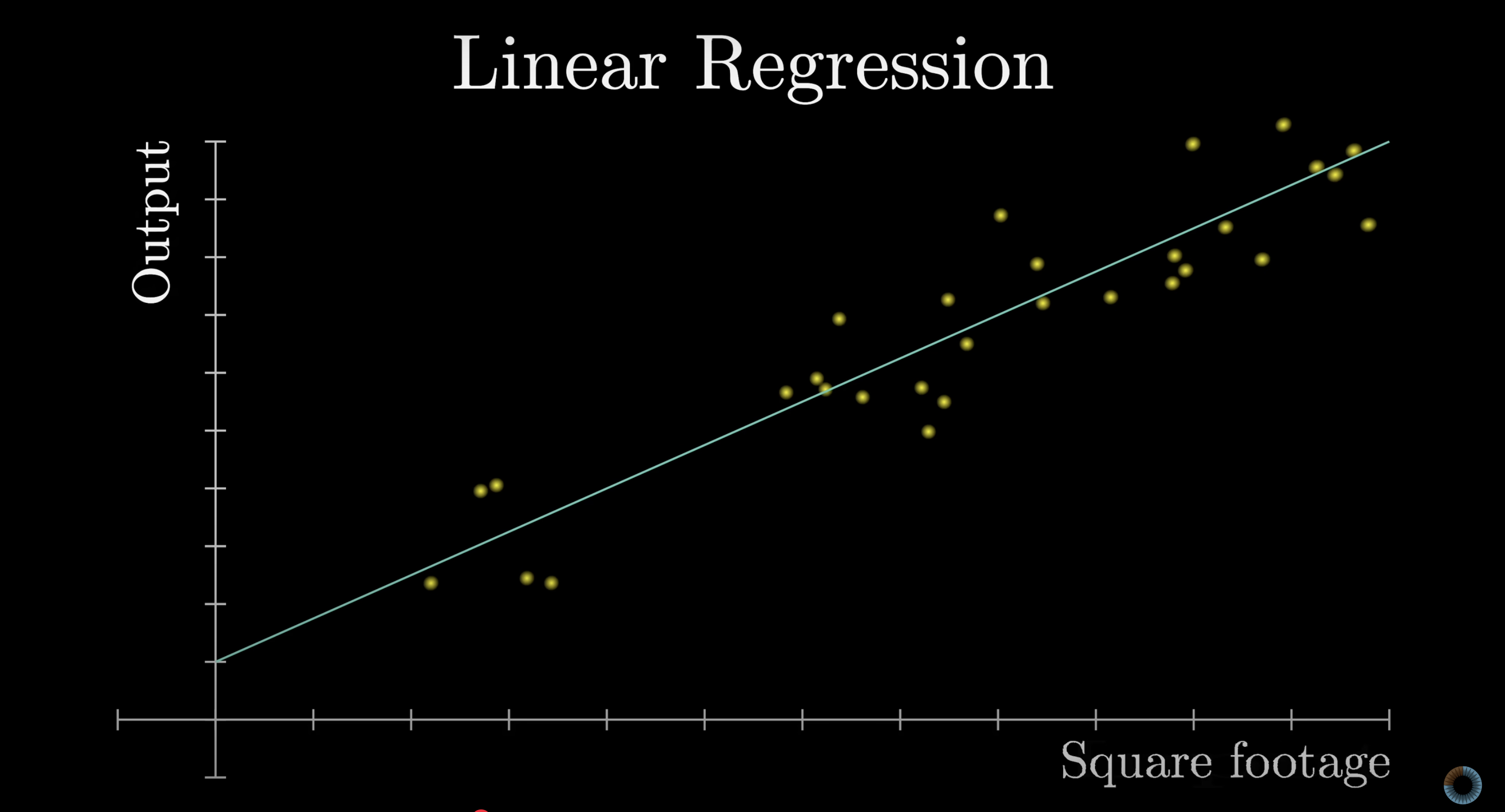
A familiar warm-up: fitting a line (simple ML)
Deep learning uses neural networks, which scale to absurd complexity. GPT-3 had 175 billion parameters. The input must be formatted as an array of numbers (a tensor), and the data gets progressively transformed through many layers until you get the final output. The parameters are usually called weights, because most of the math boils down to weighted sums, packaged as matrix-vector products.
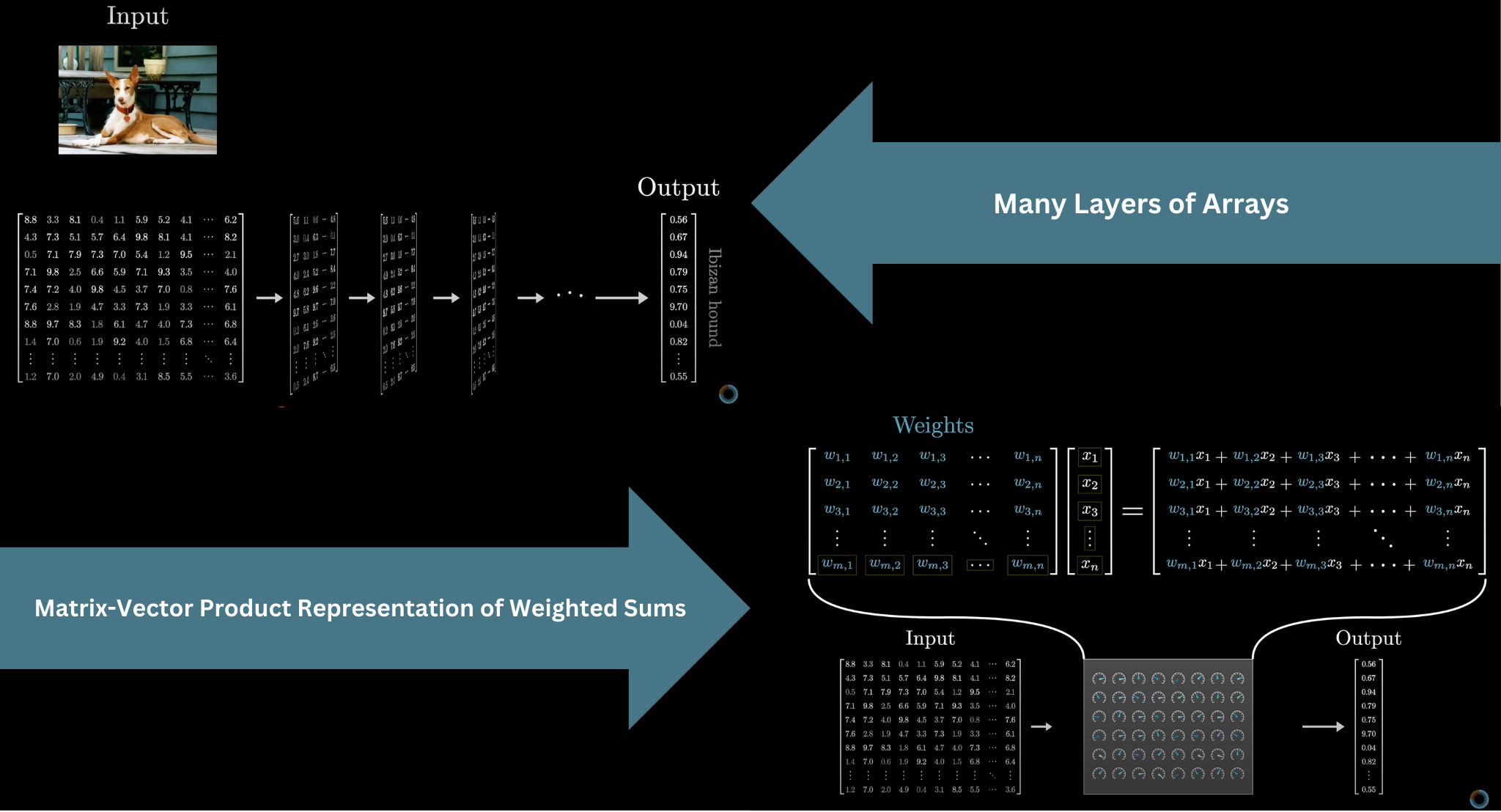
Data flows through layers as arrays of numbers
GPT-3's 175 billion weights are organized into about 28,000 matrices across 8 categories. Moving forward, we'll distinguish between the weights of the model (the learned parameters, shown in blue/red) and the data being processed (the input, shown in grey).
Embedding Matrix
The model has a predefined vocabulary: a list of all possible tokens, roughly 50,000 of them. The first matrix in the transformer, the embedding matrix $W_E$, has one column per token. Each column determines what vector that token maps to. Like every other matrix we'll see, its values start random and get refined during training.
In GPT-3, the embedding dimension is 12,288, so each token becomes a 12,288-dimensional vector. With a vocabulary of 50,257 tokens, the embedding matrix alone accounts for 617,558,016 weights.
Geometry of Word Embeddings
During training, models tend to settle on embeddings where directions in the space encode meaning. Searching for the words whose embeddings are closest to "tower" reveals words with a similar vibe.
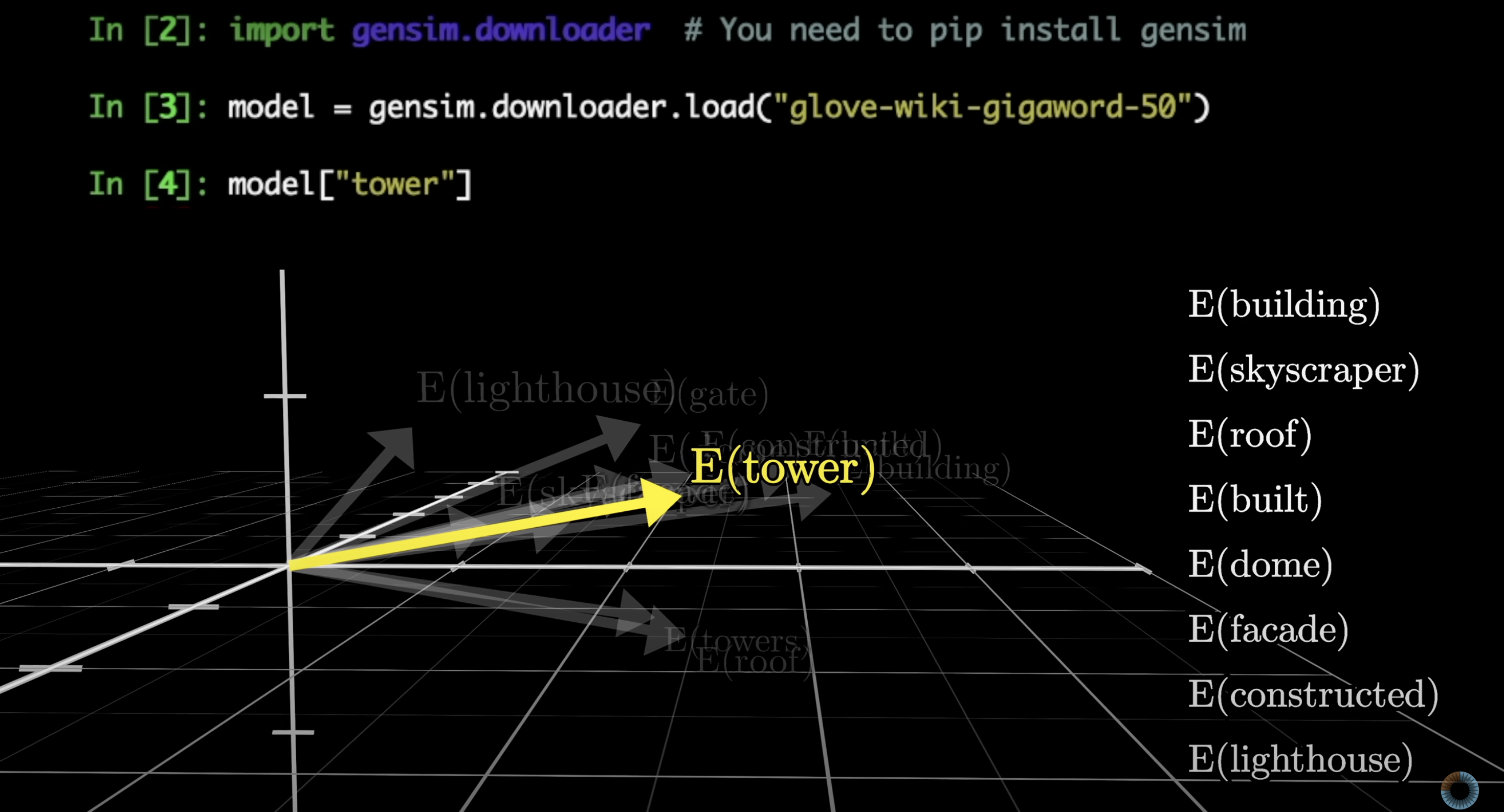
Similar meanings tend to cluster in embedding space
A classic example: the difference between the vectors for woman and man is similar to the difference between king and queen. If you take "king," add the direction of "woman" minus "man," you land near "queen." Family relations illustrate the idea even better.
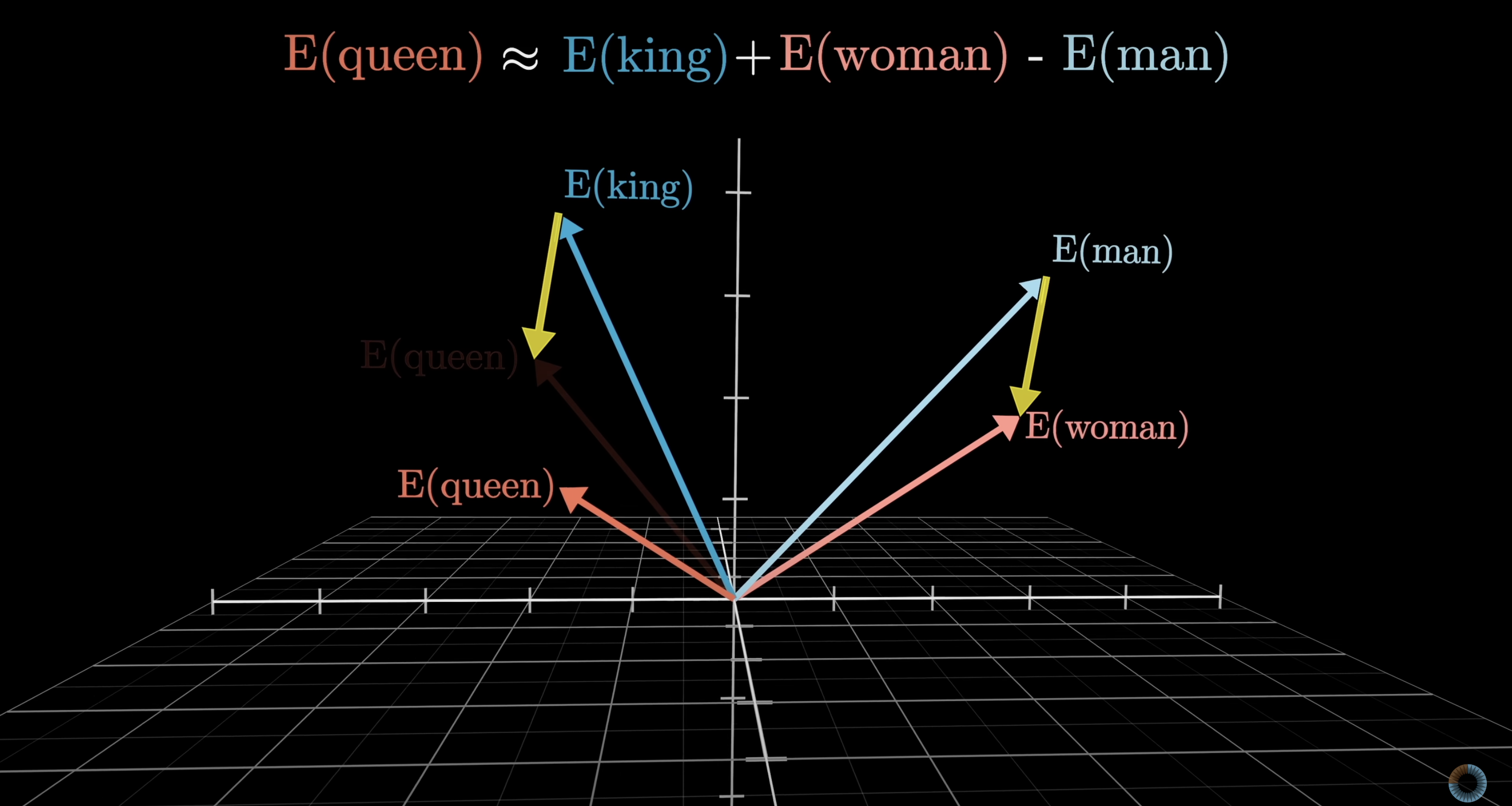
Embedding directions can encode relationships
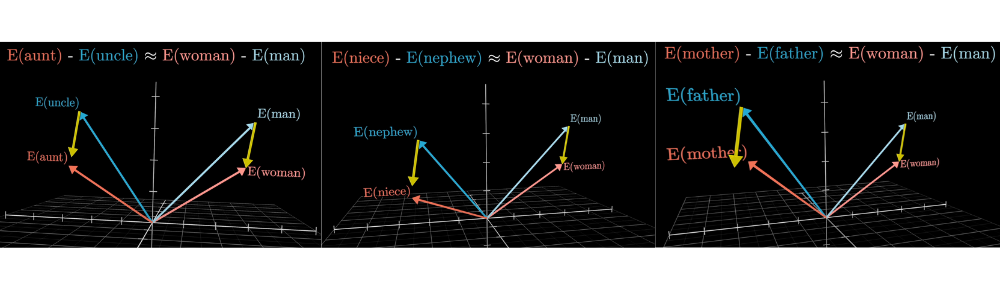
One direction in embedding space encodes gender information
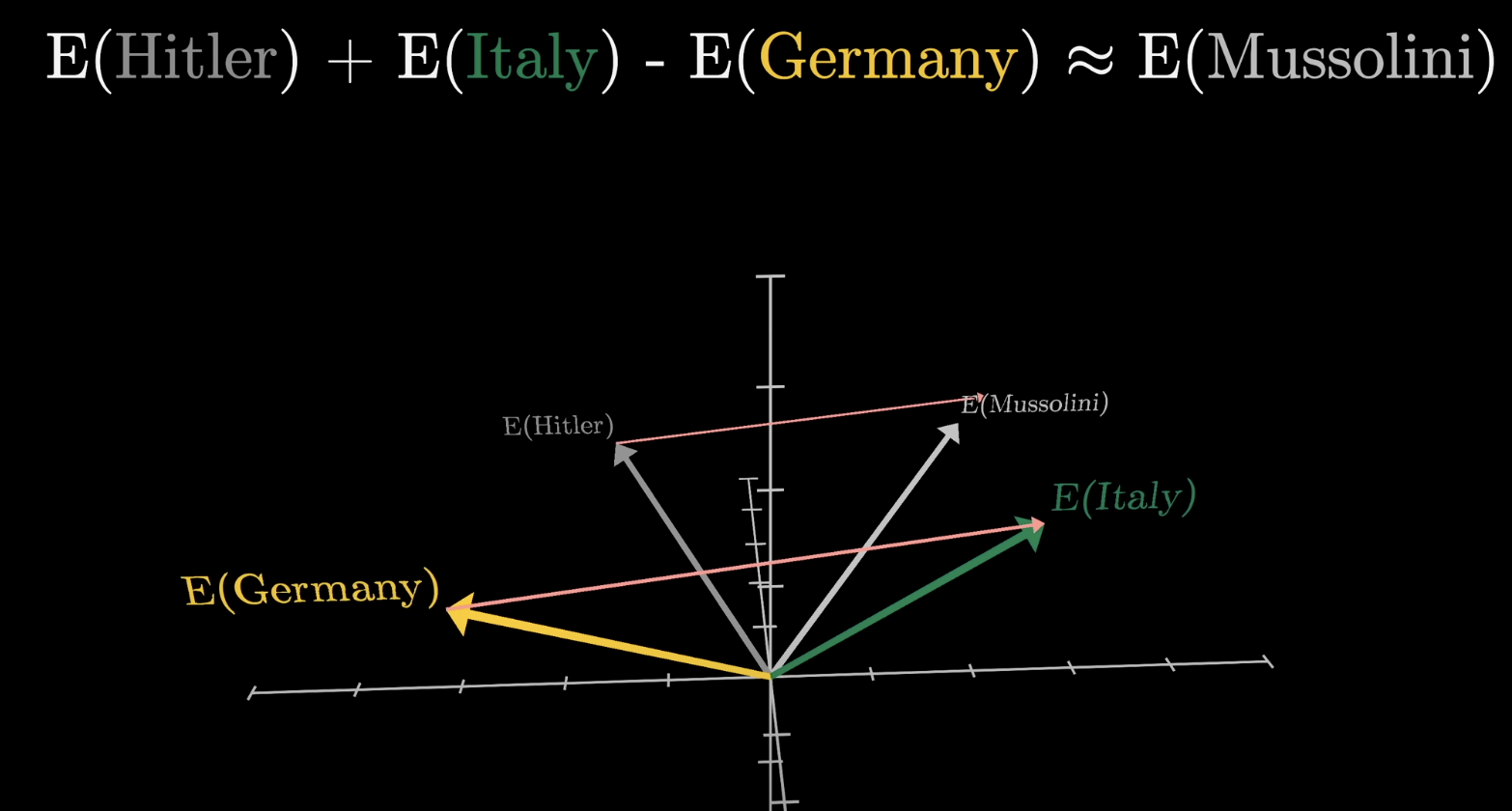
Directions can encode nationality and historical roles
Dot Product
Remember dot products? I certainly hope so. In either case, let's recap how they are used to represent alignment between vectors. They are:
- positive when they point the same way,
- zero when perpendicular,
- negative when they point in opposite directions.
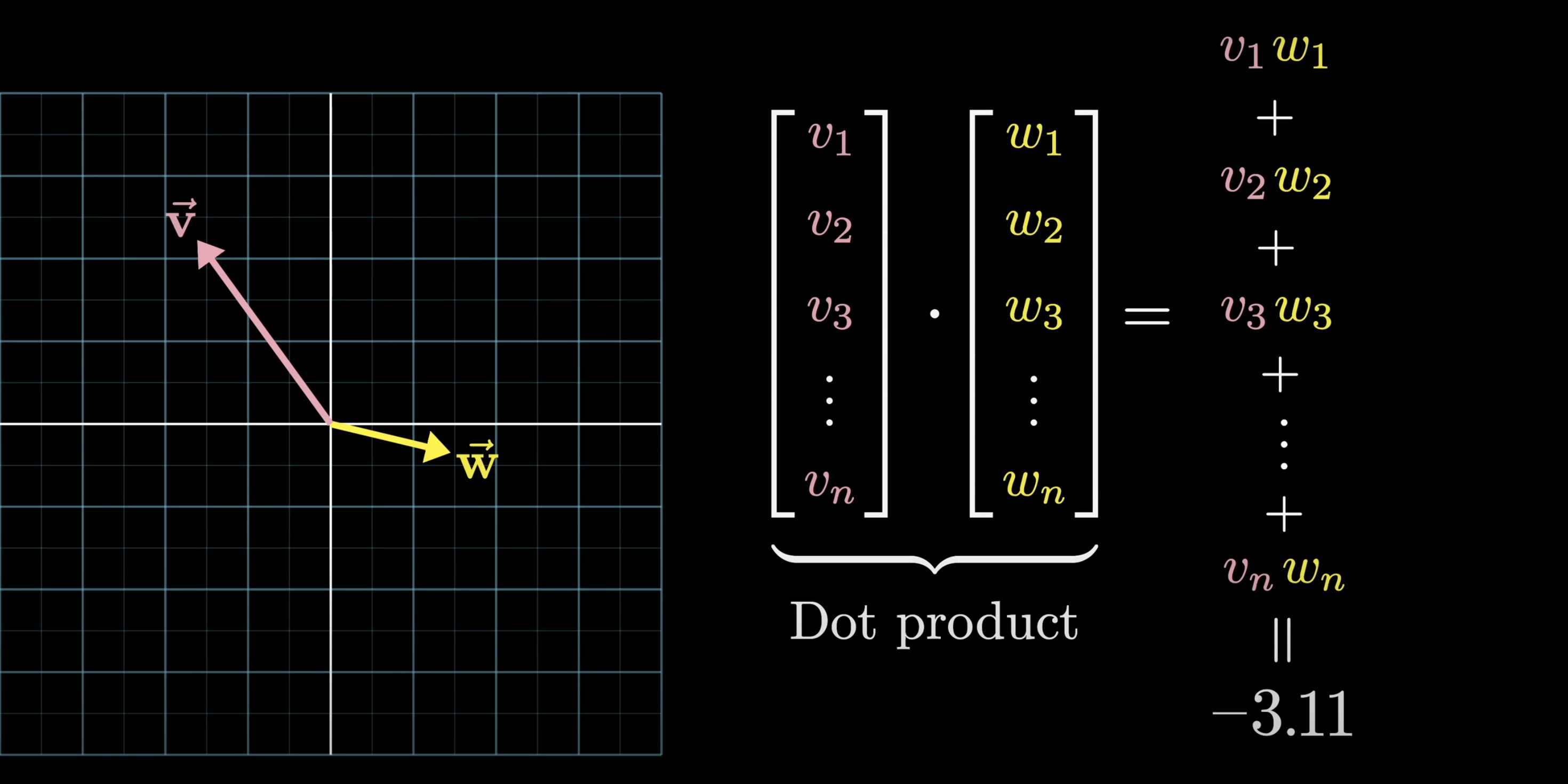
Dot products measure alignment between vectors
For example, suppose we test whether "cats" minus "cat" represents a plurality direction. Taking the dot product of this difference vector with various singular and plural nouns shows that plural words consistently score higher. Dot it with "one," "two," "three," "four" and you get increasing values, as if the model actually quantifies how plural a word is.
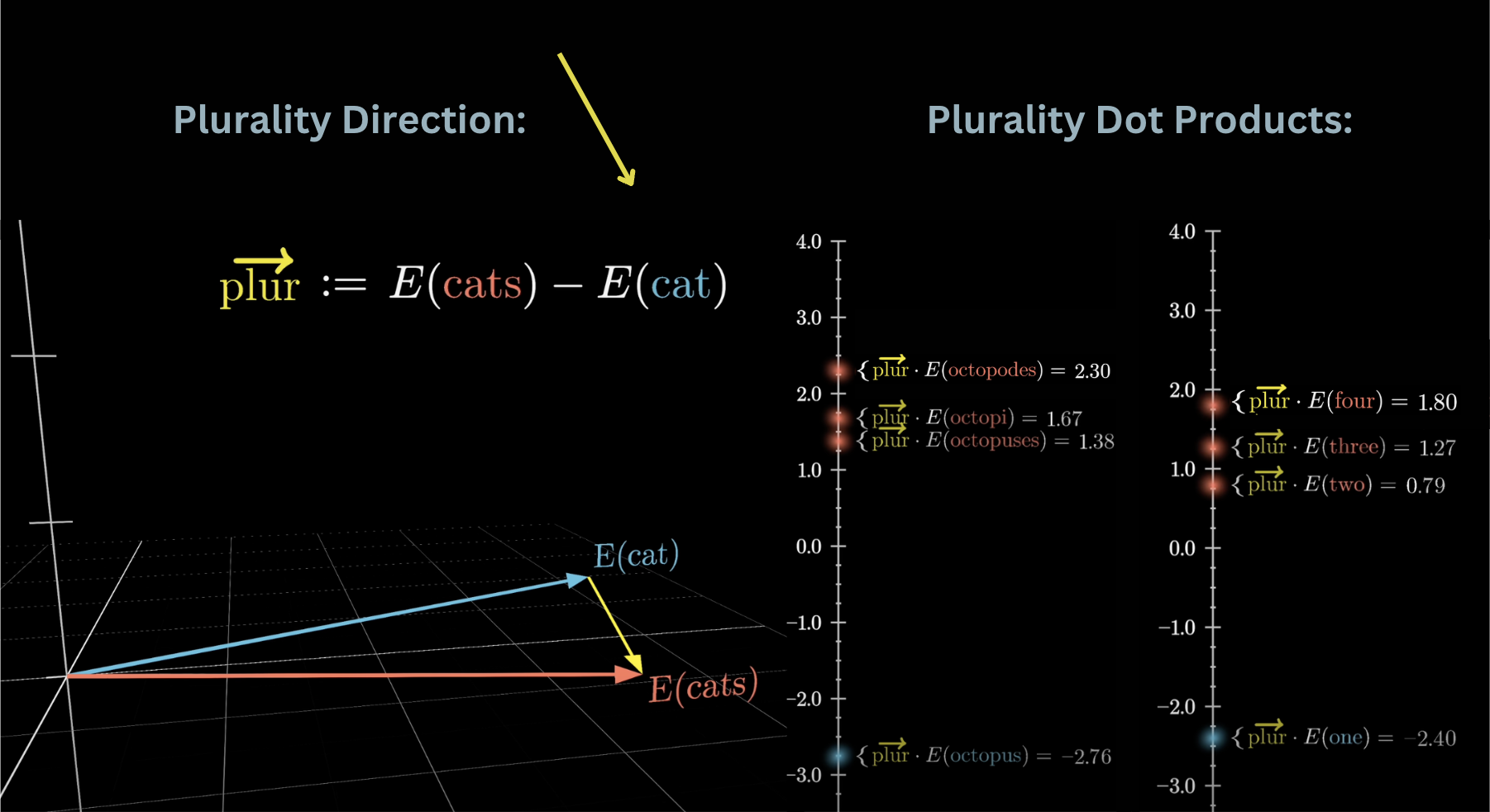
Dot products can test for semantic directions like plurality
Beyond Words
Inside a transformer, these vectors don't just represent individual words. They also encode position, and more importantly, they soak in context as they pass through layers. A vector that starts as the embedding of "king" might, after several layers, encode a king who lives in Scotland, murdered his way to the throne, and speaks in Shakespearean English.

After many layers, the "king" vector encodes rich contextual meaning
The model can only look at a fixed number of vectors at a time, known as its context size. For GPT-3, that was 2,048 tokens. This hard limit on how much text the model can "see" is why early versions of ChatGPT would lose the thread in long conversations.
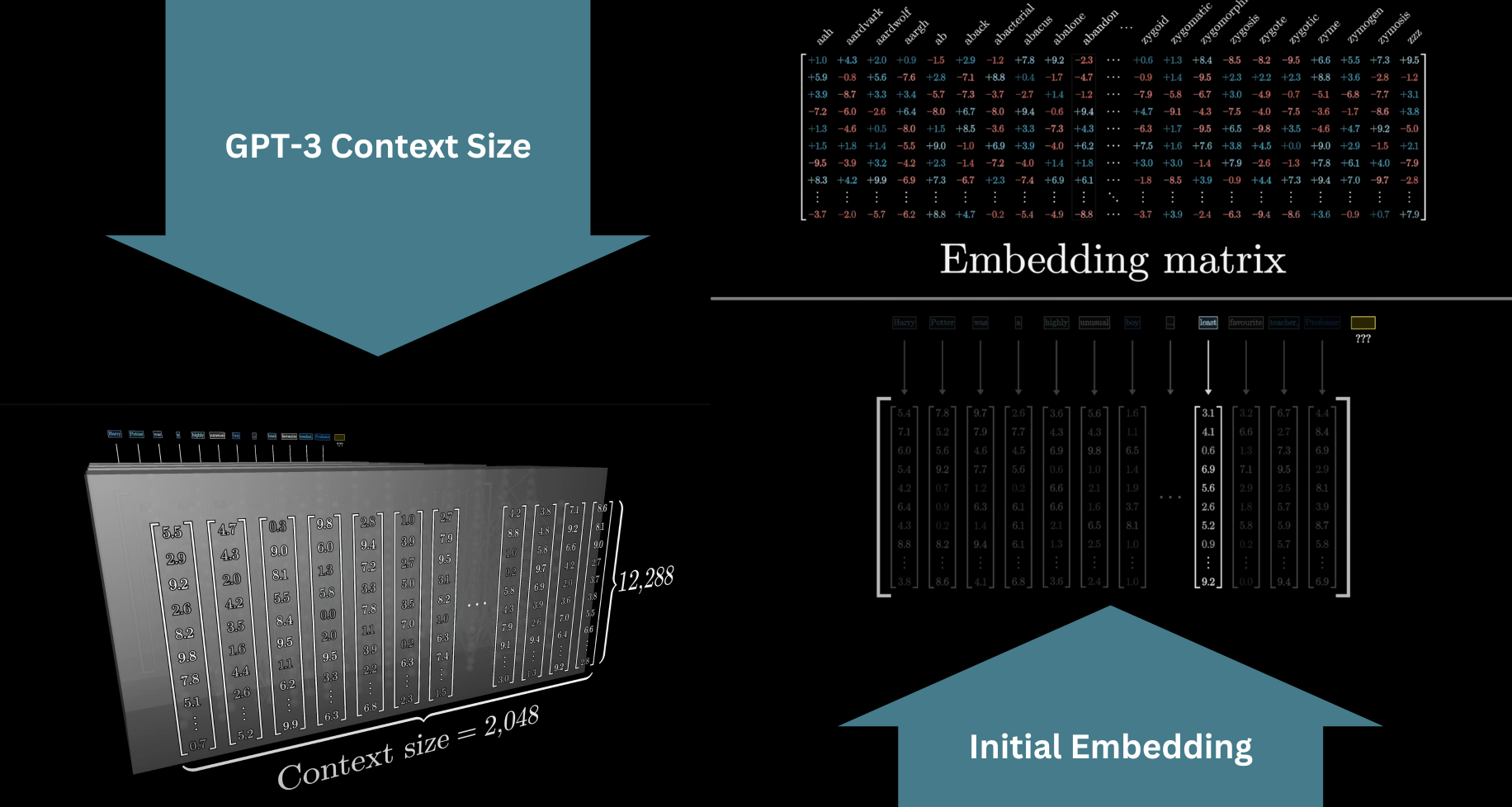
Context window: the fixed number of tokens the model can see at once
Unembedding
At the very end of the transformer, the model needs to turn its internal vectors back into a prediction. For instance, if the context includes words like "Harry Potter" and the immediately preceding text is "least favorite Professor," a well-trained network should assign a high probability to "Snape."
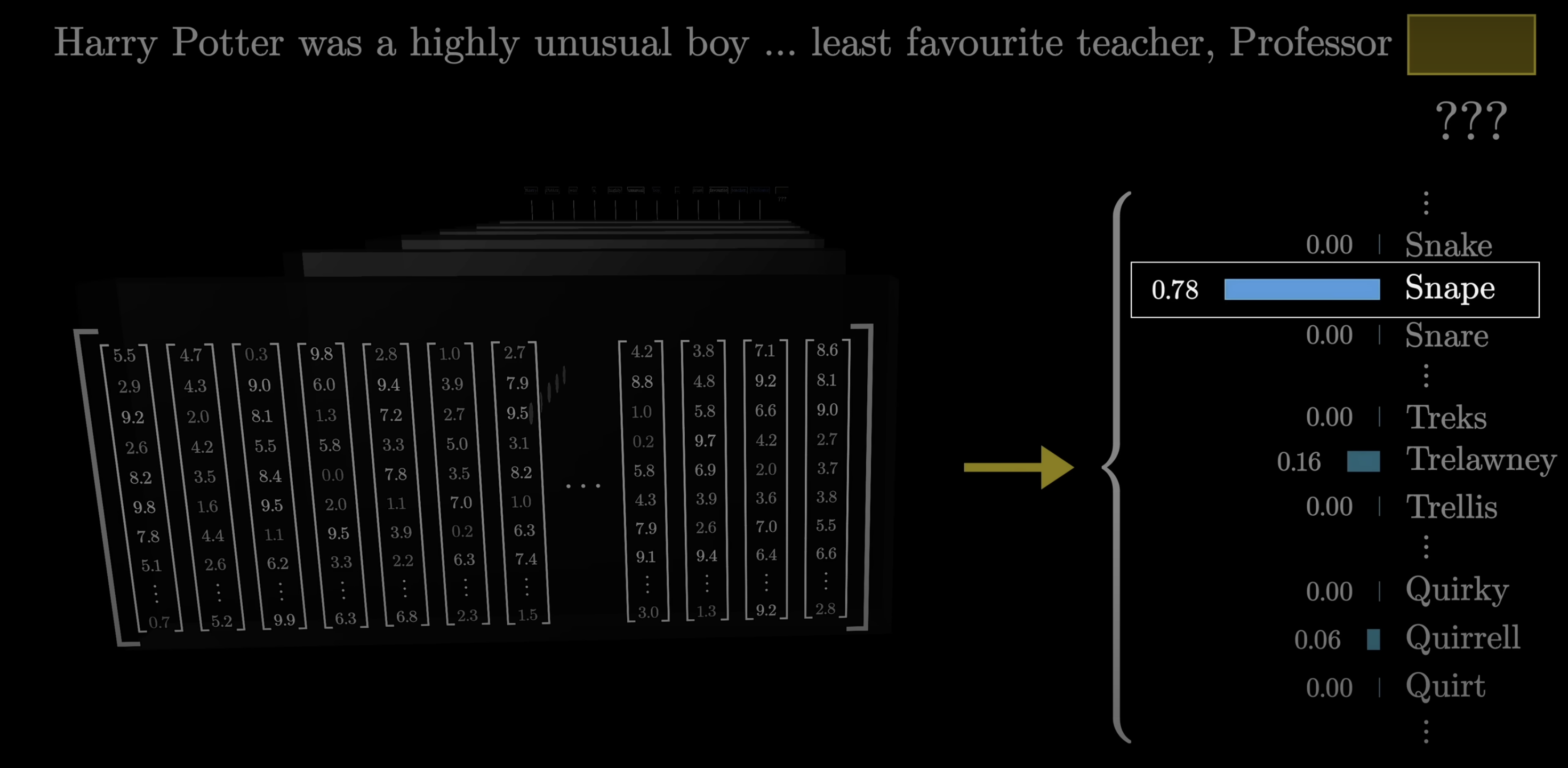
The model predicts the next token from context
This works via an unembedding matrix $W_U$ that maps the last vector in the context to a list of ~50,000 values, one per vocabulary token. The matrix has 50,257 rows and 12,288 columns, adding another ~617 million parameters. Combined with the embedding matrix, that's already over a billion parameters. A small but real fraction of GPT-3's 175 billion total.
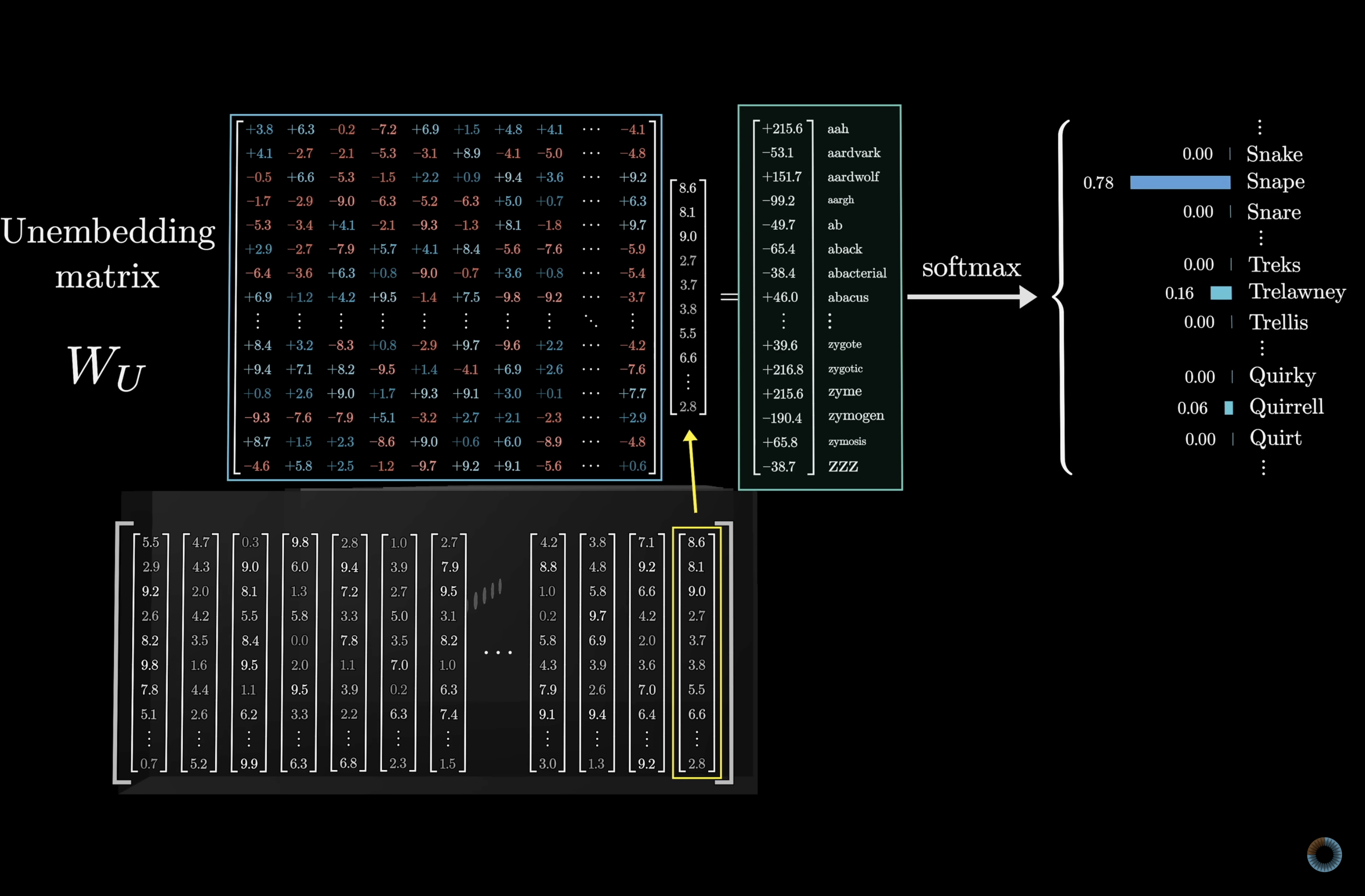
Unembedding matrix: vector → score for each token
Softmax
For a valid probability distribution, all values need to be between 0 and 1 and sum to 1. The raw outputs of a matrix-vector product don't satisfy either constraint: values can be negative, greater than 1, and they certainly don't sum to 1. Softmax fixes this. It turns any list of numbers into a valid distribution where the largest values end up near 1 and smaller values end up near 0.
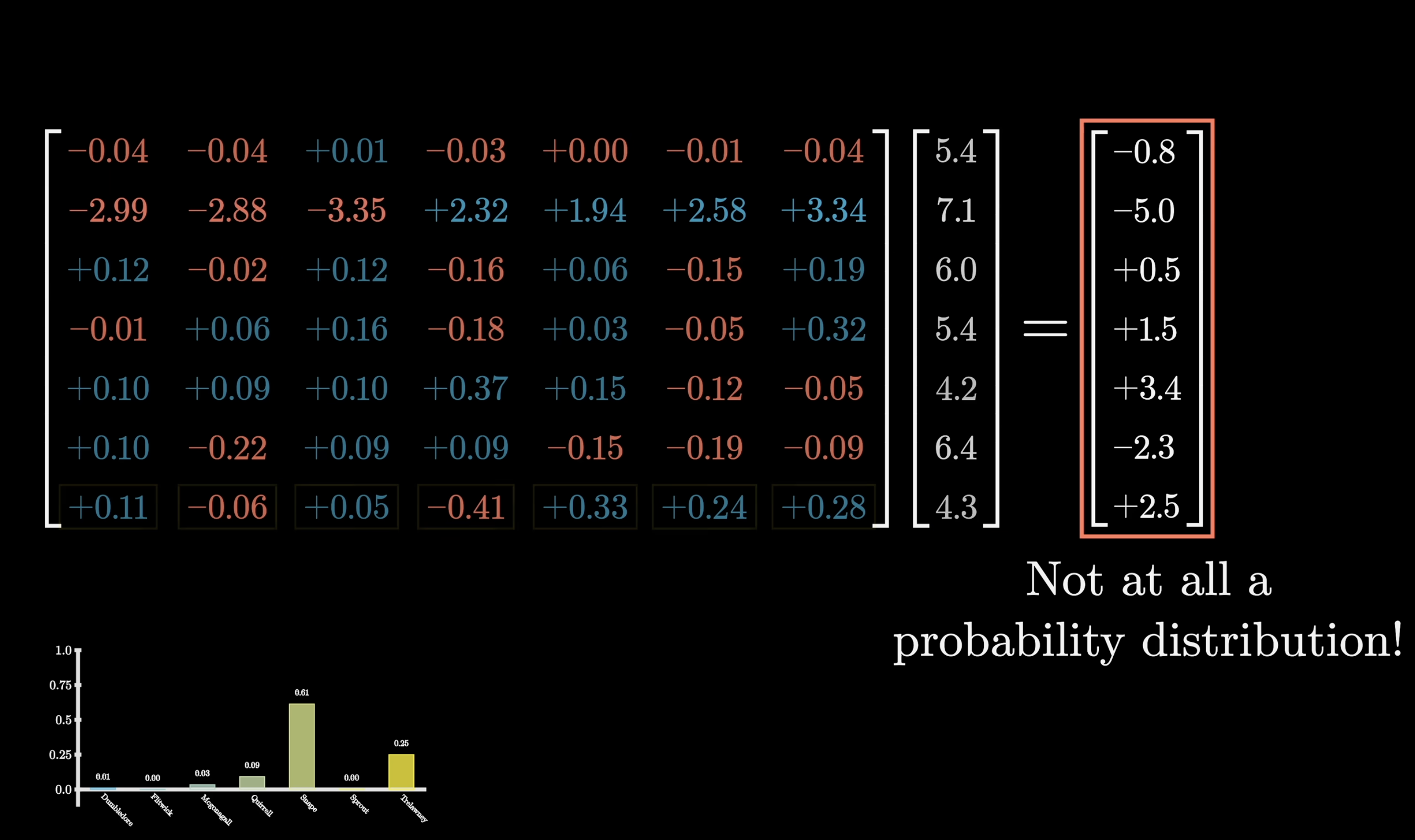
The raw output is not a valid probability distribution
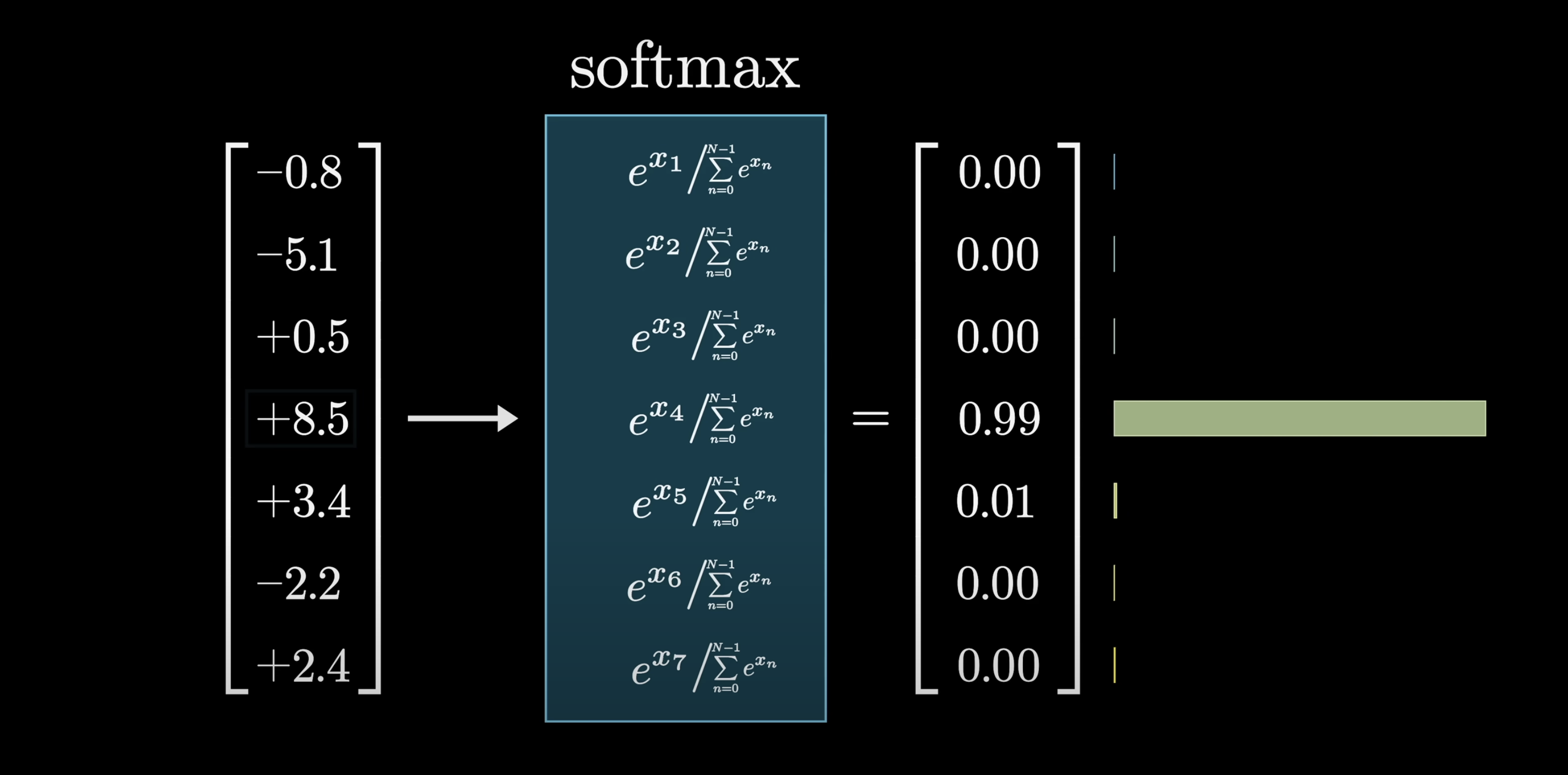
Softmax maps raw scores → probabilities
The mechanics: raise $e$ to the power of each number (making everything positive), then divide each term by the total (so the values sum to 1). If one entry is much larger than the rest, its output is practically 1, and sampling from the distribution is basically just picking the max.
Temperature
A temperature parameter $T$ reshapes the distribution. Higher $T$ spreads weight more evenly across values (more randomness). Lower $T$ concentrates weight on the top values (more greedy). At $T = 0$, it's purely deterministic: all weight goes to the max.
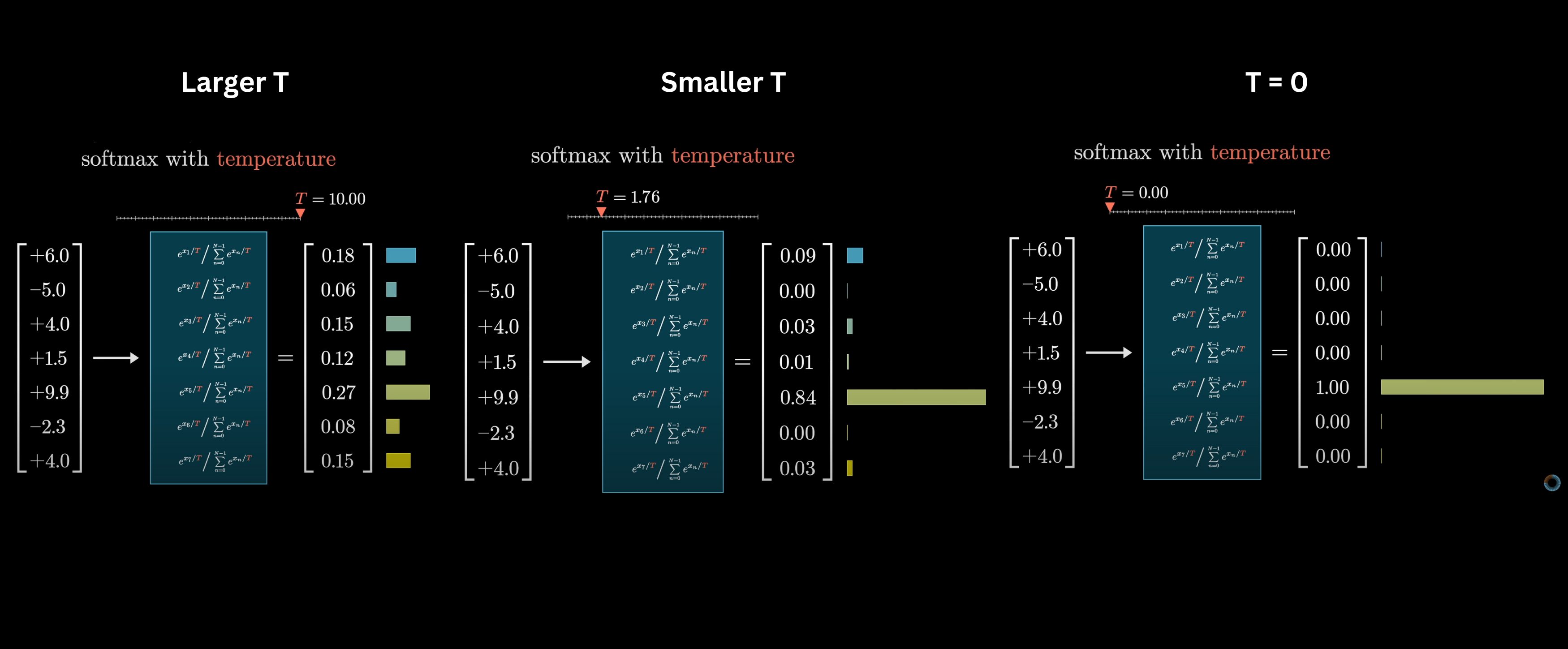
Temperature controls how spread out the distribution is
Logits
The raw, unnormalized scores fed into softmax are called logits. When you feed text through the network and multiply by the unembedding matrix, the resulting values are the logits for the next-token prediction.
Conclusion
You now have the building blocks: embeddings that encode meaning as vectors, dot products that measure similarity, softmax that turns scores into probabilities, and matrices full of learnable weights tying it all together.